|
I am a PhD student at the University of Illinois, Urbana Champaign, advised by Prof. Heng Ji. Previously, I was an AI Resident at IBM Research, New York wherein I had the pleasure of working with Vittorio Castelli, Avirup Sil and Salim Roukos. I graduated from Indian Institute of Technology Madras in 2018 with a bachelors degree in computer science. While at IIT Madras, I worked with Prof. Mitesh Khapra and Prof. Balaraman Ravindran Email / CV / LinkedIn / Google Scholar |

|
|
I'm interested in natural language processing and large language models, particulary in the fields of agentic search, embedding models and reranking, and information-seeking for retrieval-augmented generation. |
|
|
|
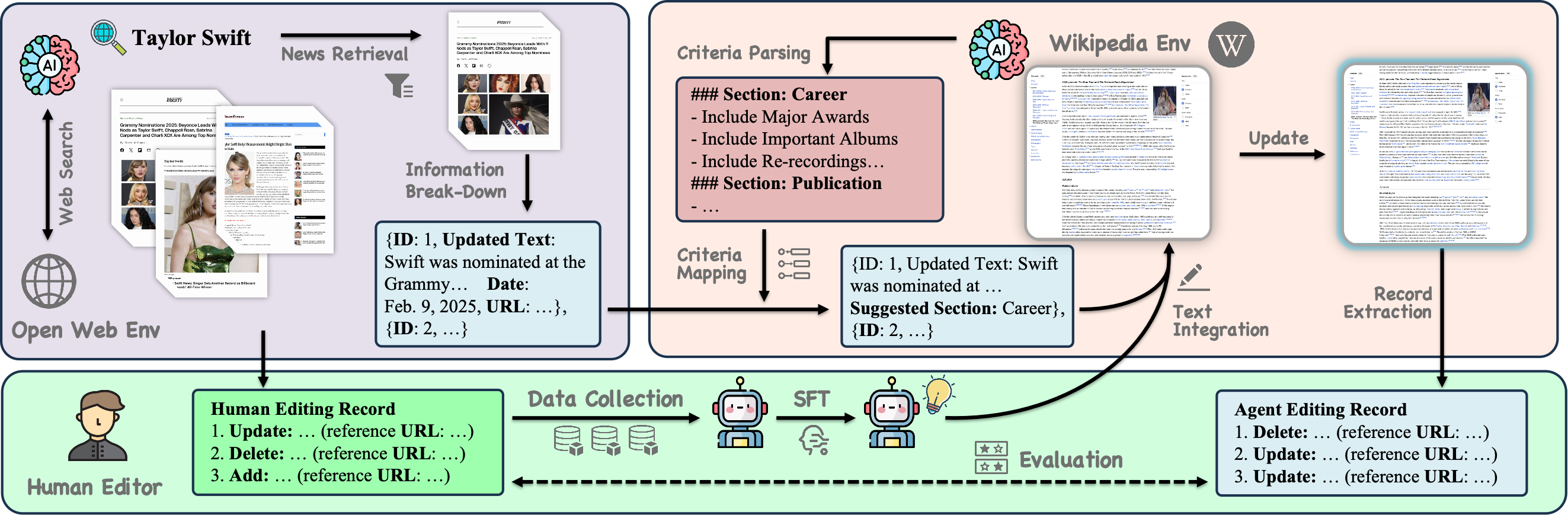
Revanth Reddy*, Tanay Dixit*, Jiaxin Qin, Cheng Qian, Daniel Lee, Jiawei Han, Kevin Small, Xing Fan, Ruhi Sarikaya, Heng Ji Under Review We introduce WiNELL, an agentic framework for automatic wikipedia updating, that continuously monitors online sources for recent facts, identifies relevant updates for the Wiki article under consideration, and generates well-formed edit suggestions. |
|
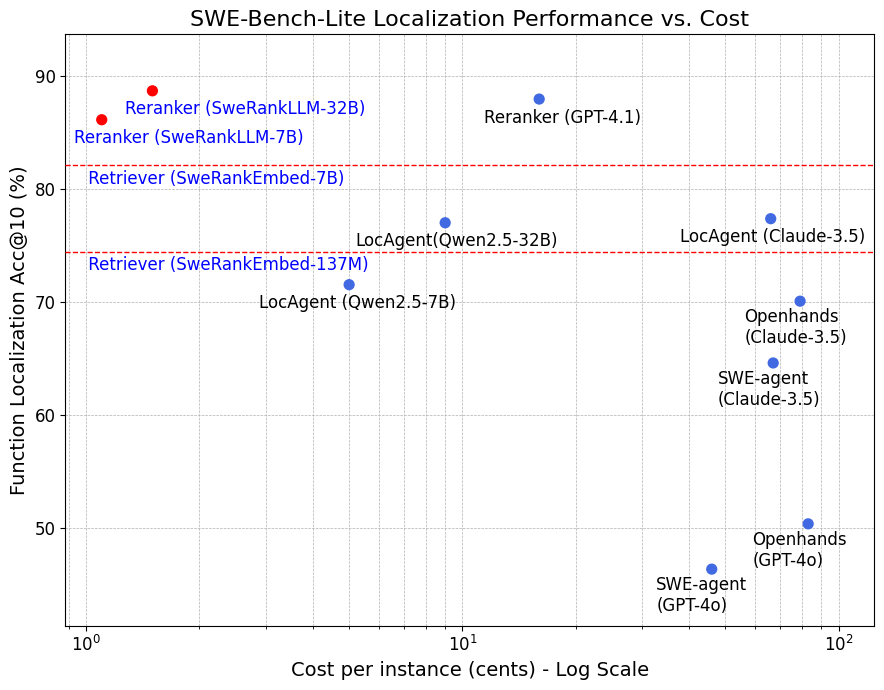
Revanth Reddy*, Tarun Suresh*, JaeHyeok Doo, Ye Liu, Xuan Phi Nguyen, Yingbo Zhou, Semih Yavuz, Caiming Xiong, Heng Ji, Shafiq Joty Under Review [Paper][Blog Post][Code] We introduce SWERank, a code ranking framework for software issue localization, which identifies the relevant code that needs to be modified to fix a software issue. |
|
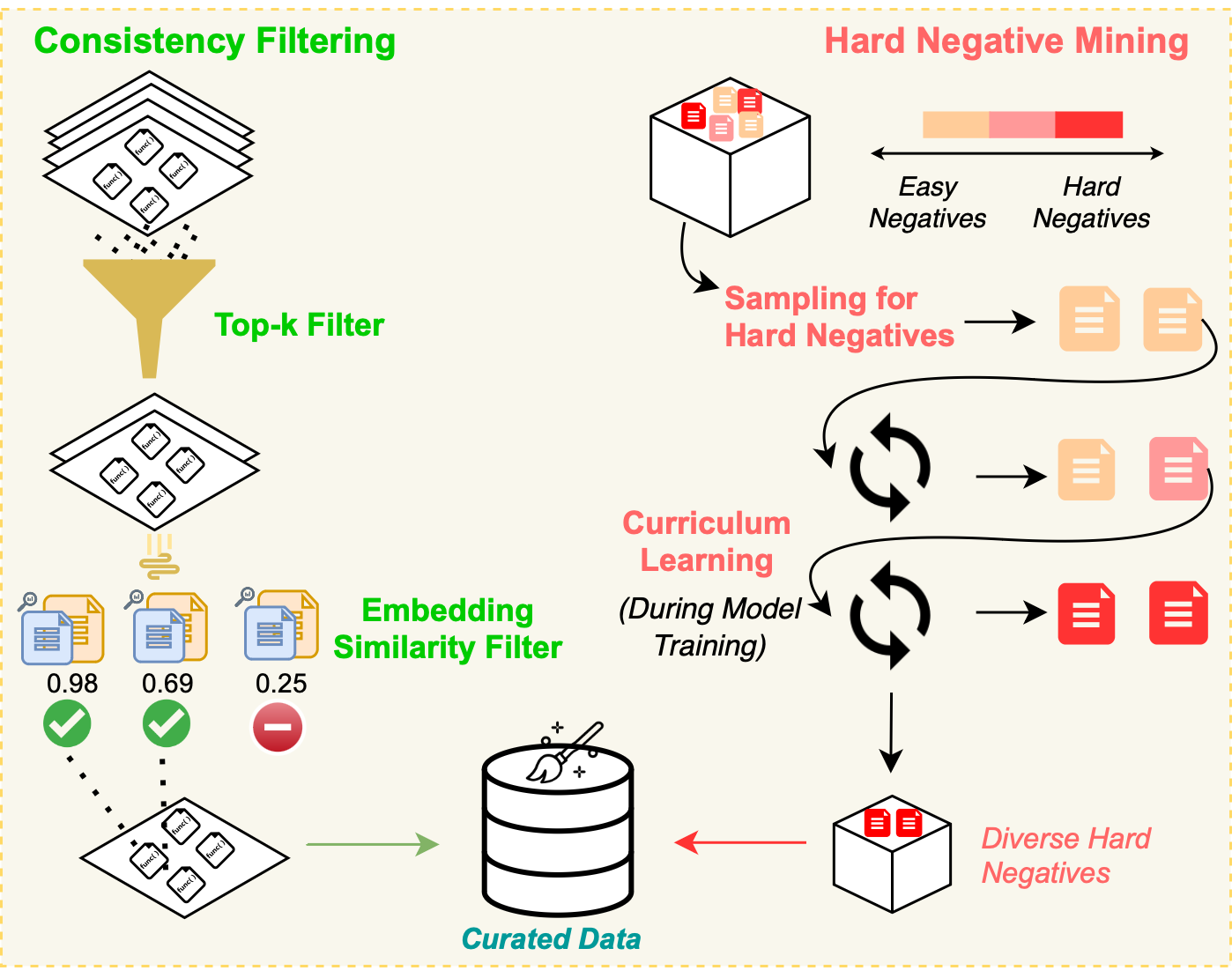
Tarun Suresh*, Revanth Reddy*, Yifei Xu, Zach Nussbaum, Andriy Mulyar, Brandon Duderstadt, Heng Ji ICLR 2025 [Paper][Blog Post][Code] We introduce CoRNStack, a large-scale, high-quality contrastive training dataset for code that spans multiple programming languages. We demonstrate that contrastive training of embedding models using CoRNStack leads to state-of-the-art performance across a variety of code retrieval tasks. |
|
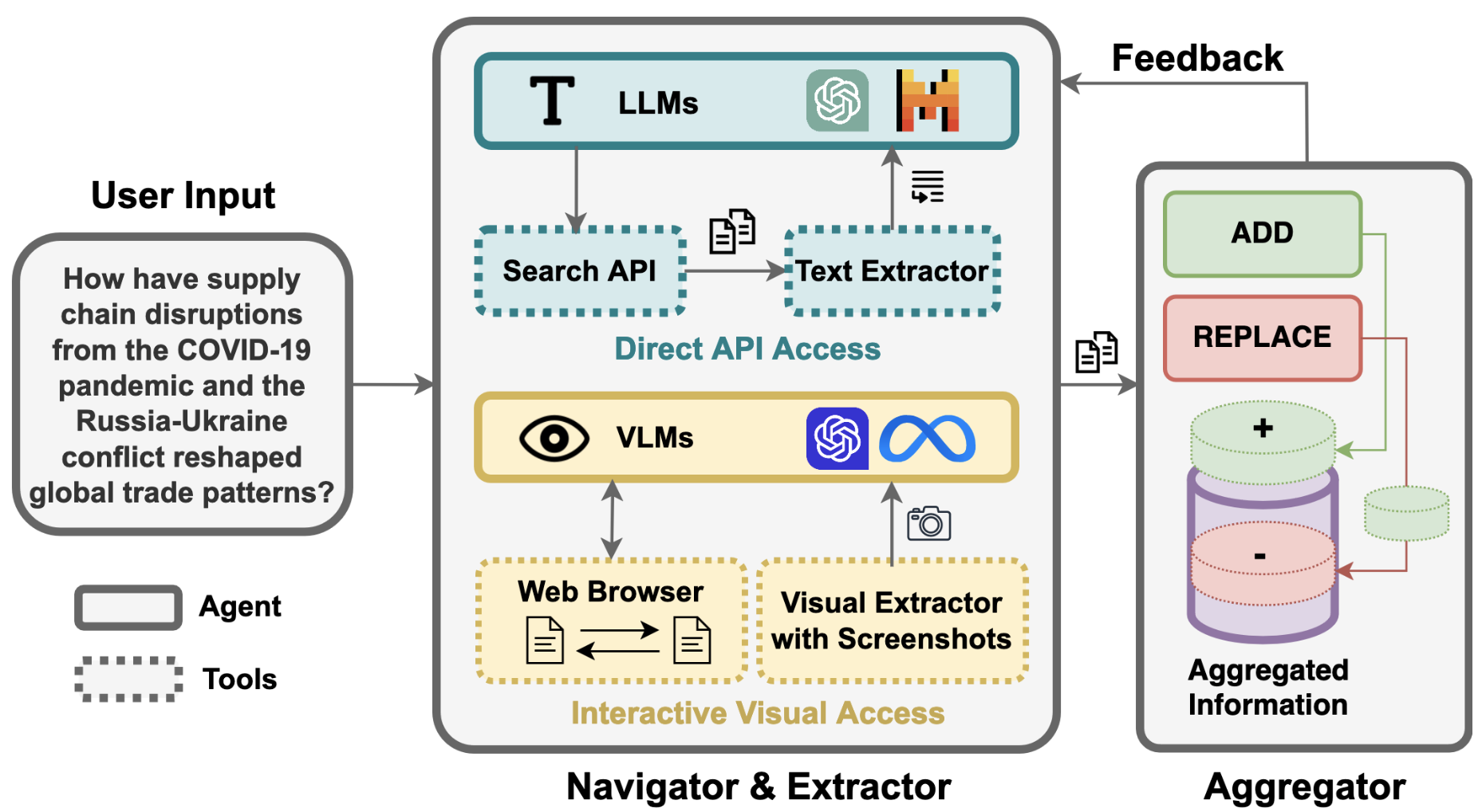
Revanth Reddy*, Sagnik Mukherjee*, Jeonghwan Kim*, Zhenhailong Wang*, Dilek Hakkani-Tur, Heng Ji NAACL Findings, 2025 [Paper][Blog Post][Code] We introduce INFOGENT,a novel modular and feedback-driven framework for web information aggregation involving three distinct components: Navigator, Extractor and Aggregator. |
|
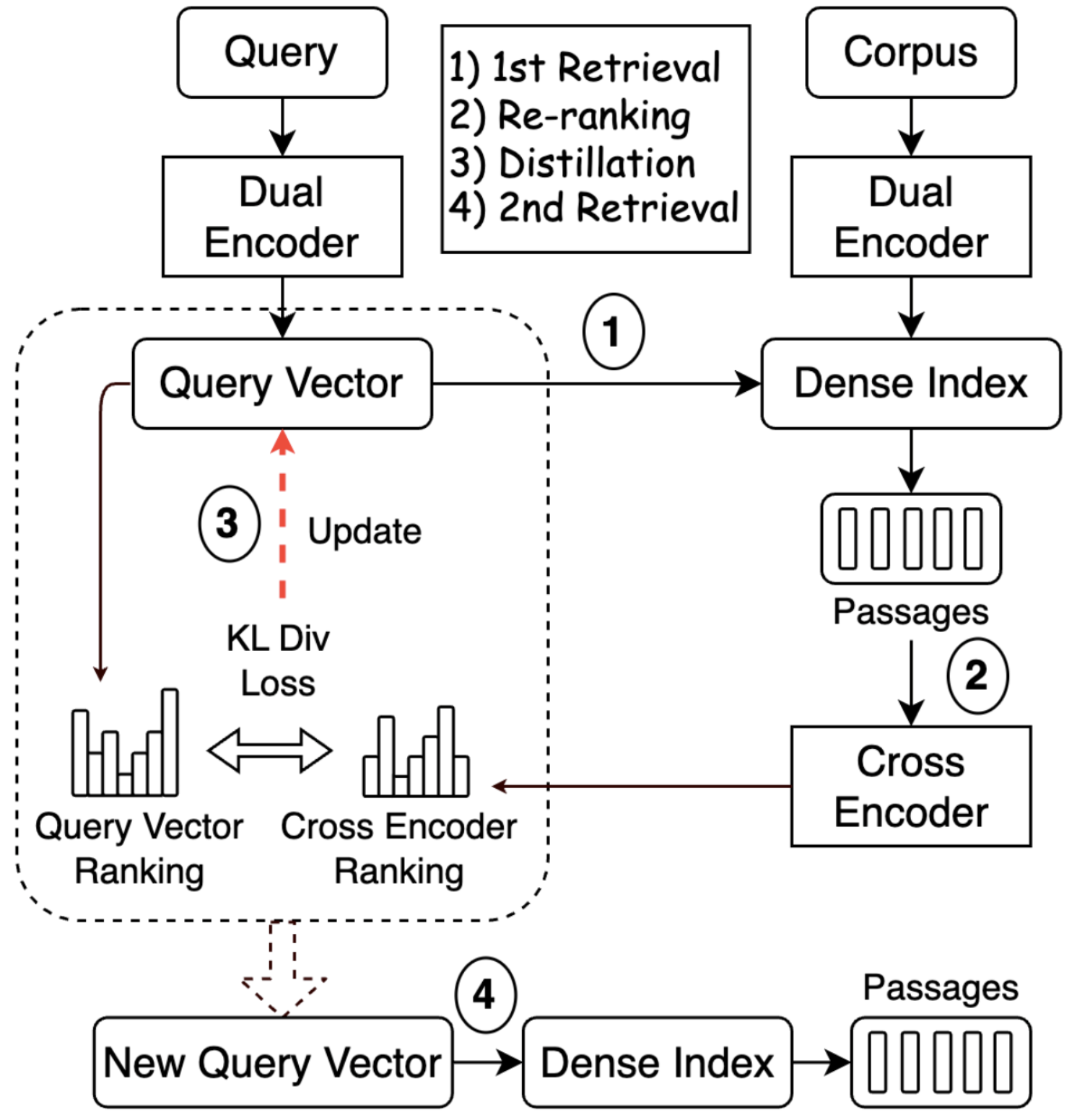
Revanth Reddy, Pradeep Dasigi, Md Arafat Sultan, Arman Cohan, Avi Sil, Heng Ji Hannaneh Hajishirzi SIGIR 2025 [Paper] We propose to compute an improved vector representation of the query using supervision from the re-ranker at inference time, thereby improving the retriever's Recall@K. Our approach is parameter-free, lightweight, and can serve arbitrary retrieve-and-rerank pipelines, significantly improving retrieval recall in multiple domains, languages, and modalities. |
|
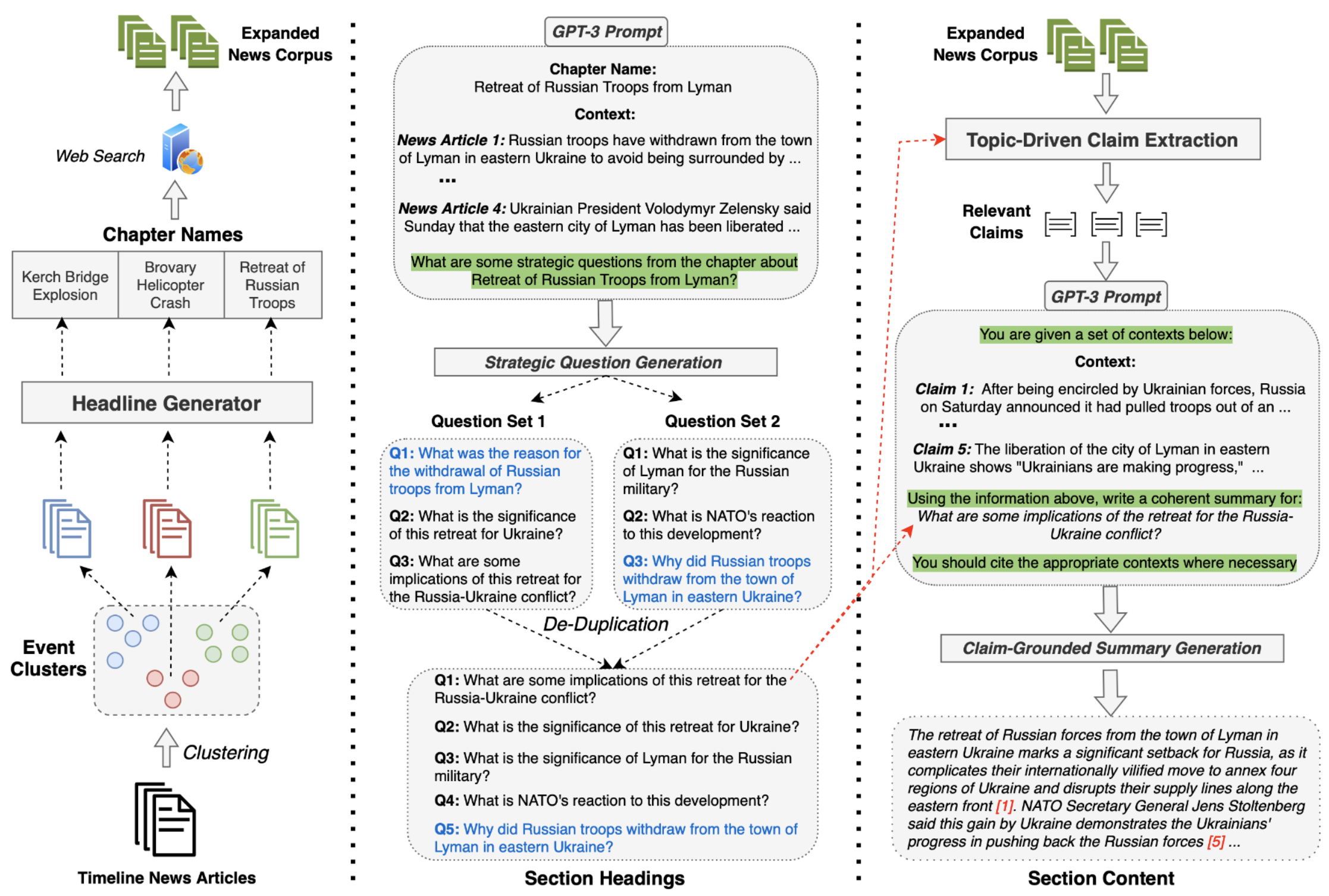
Revanth Reddy, Daniel Lee, Yi R. Fung, Qi Zeng, Manling Li, Ziqi Wang, Paul Sullivan, Clare Voss, Heng Ji Knowledge Graphs Journal, 2024 [Paper][Code] We introduce SmartBook, a generalizable automated framework designed to assist human analysts in real-time situation report generation from large news corpora, by generating a structured report with multiple hypotheses (claims) summarized and grounded with rich links to factual evidence. |
|
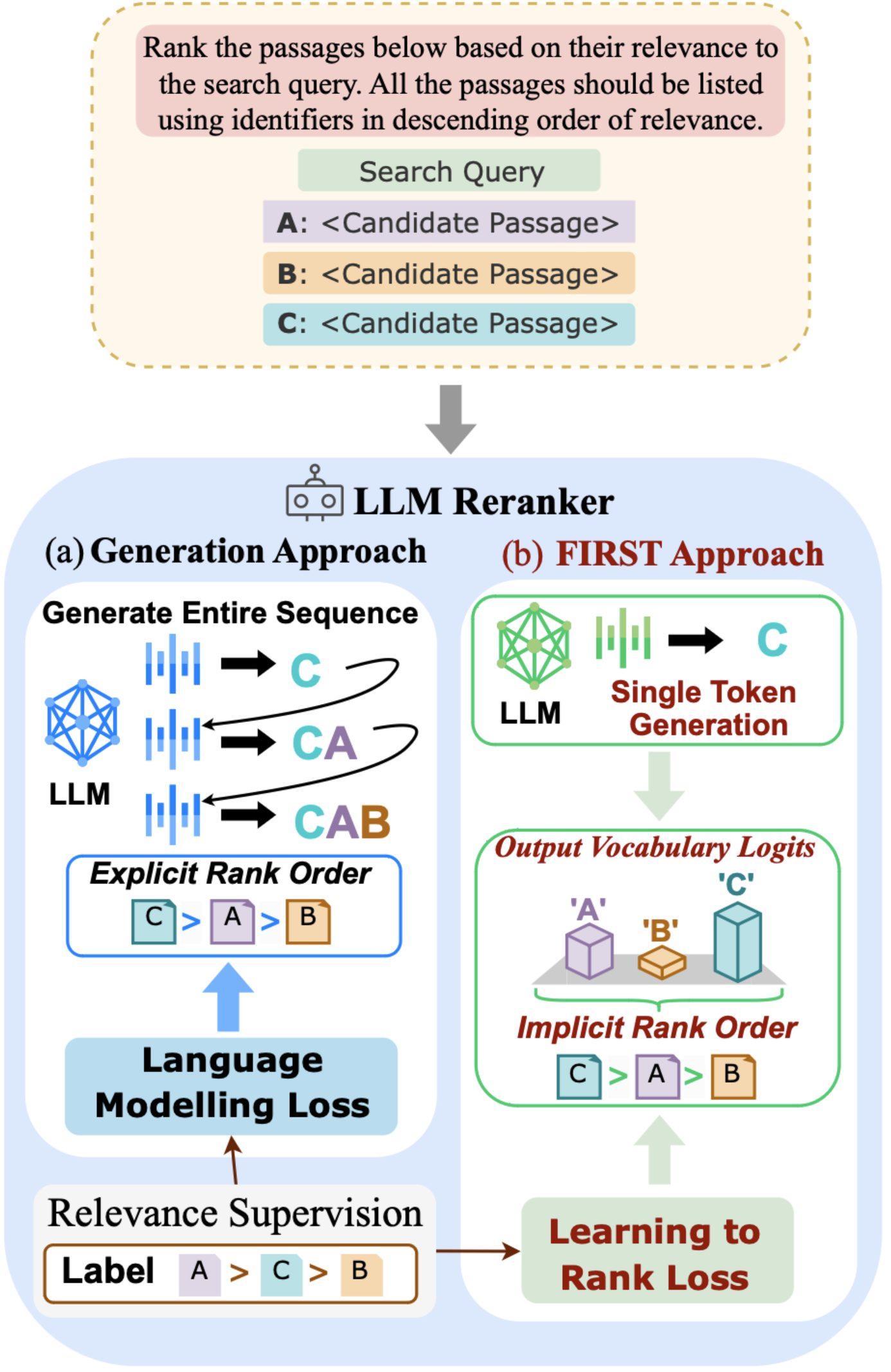
Revanth Reddy, JaeHyeok Doo, Yifei Xu, Md Arafat Sultan, Deevya Swain, Avirup Sil, Heng Ji EMNLP 2024 [Paper][Code] We introduce FIRST, a novel listwise LLM reranking approach leveraging the output logits of the first generated identifier to directly obtain a ranked ordering of the candidates. |
|
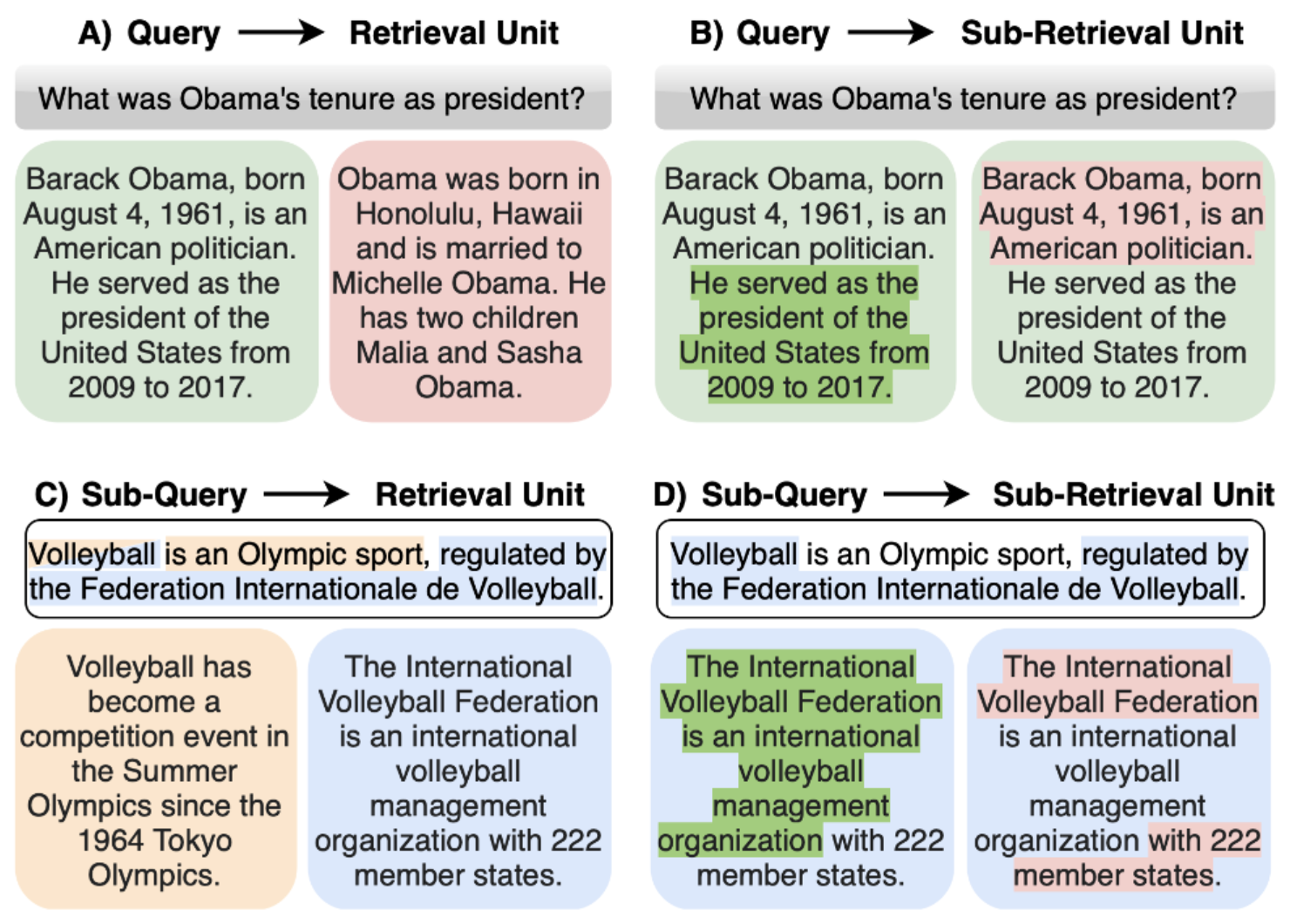
Revanth Reddy, Omar Attia, Yunyao Li, Heng Ji, Saloni Potdar EMNLP 2024 [Paper] We introduce any-granularity ranking which leverages multi-vector embeddings to rank at varying levels of granularity while maintaining encoding at a single (coarser) level of granularity. |
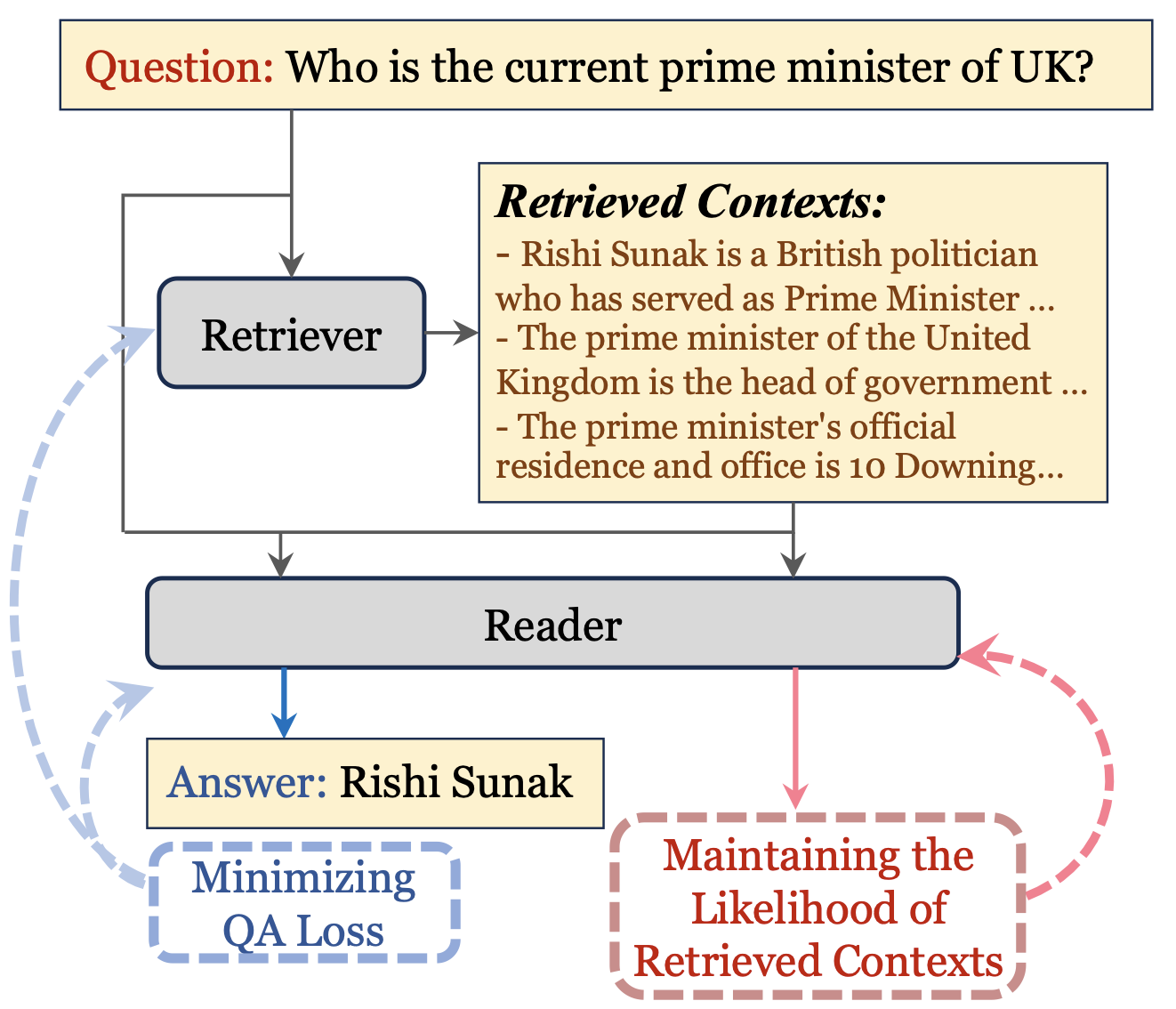
|
Zixuan Zhang, Revanth Reddy, Kevin Small, Tong Zhang, Heng Ji NAACL Findings, 2024 [Paper] We propose to improve an OpenQA model's generalizability across different corpora and domains by mitigating the model's over-memorization of knowledge. |
|
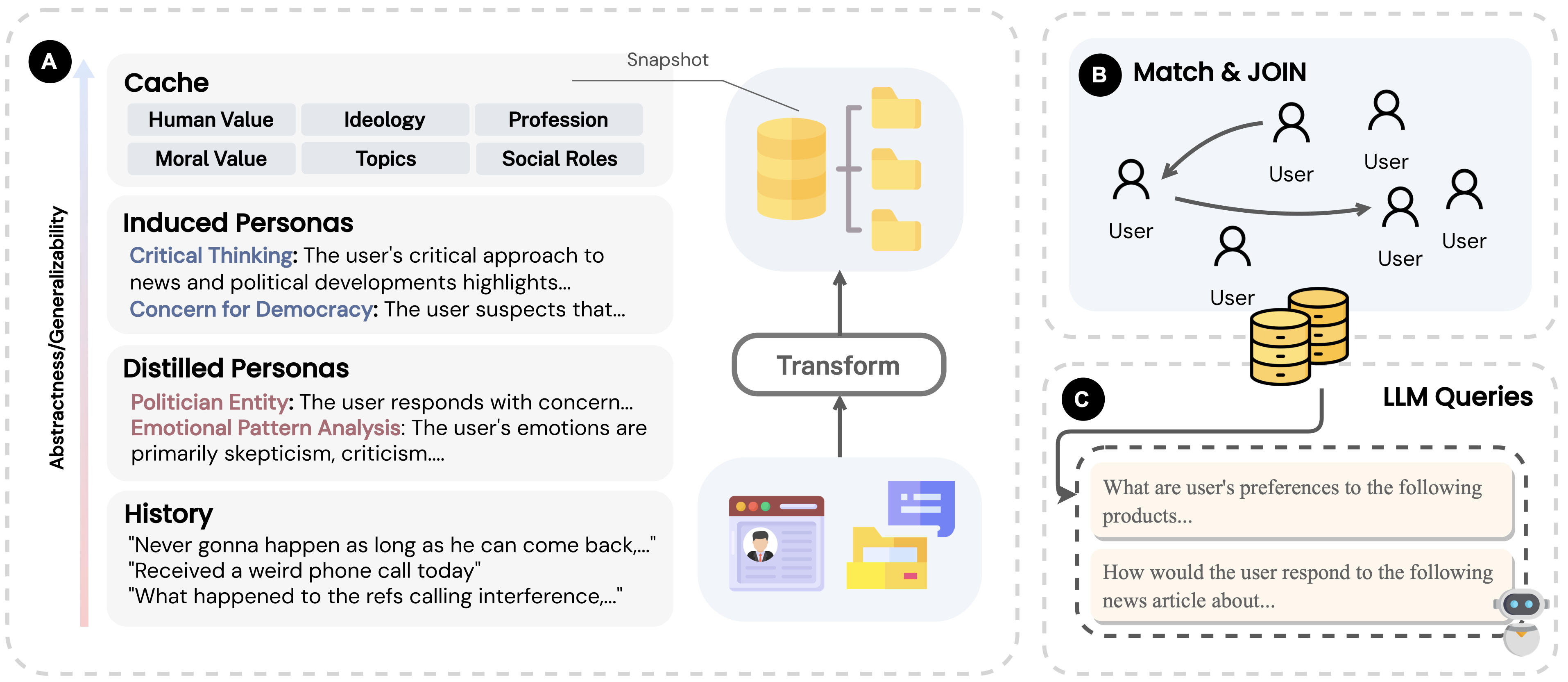
Chenkai Sun, Ke Yang, Revanth Reddy, Yi R. Fung, Hou Pong Chan, Kevin Small, ChengXiang Zhai, Heng Ji COLING 2025 [Paper] We introduce a framework that enhances the accuracy and context efficiency of retrieval-based LLM personalization through collaborative data refinement. The method also excels in cold-start scenarios. |
|
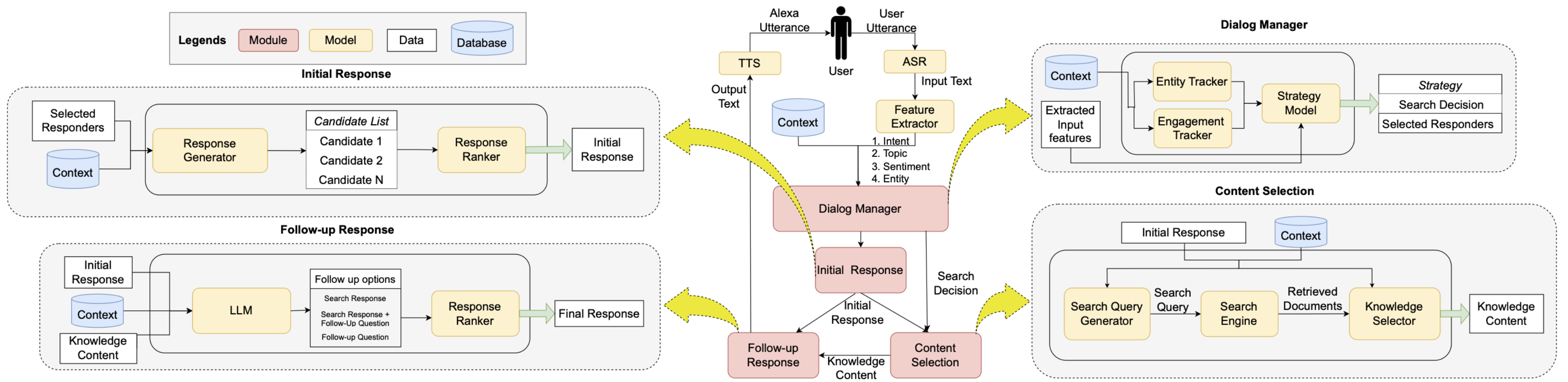
Revanth Reddy, Sharath Chandra, Hao Bai, Wentao Yao, Mankeerat Singh Sidhu, Karan Aggarwal, Prathamesh Sonawane, ChengXiang Zhai WSDM Demo, 2024 [Paper] We introduce the use of progressive response generation to integrate real-time web search results, where the preliminary response buys time for a detailed follow-up, ensuring a smooth user interaction. As a result, our method cuts down user waiting times for voice-based chatbots by 50%. |
|
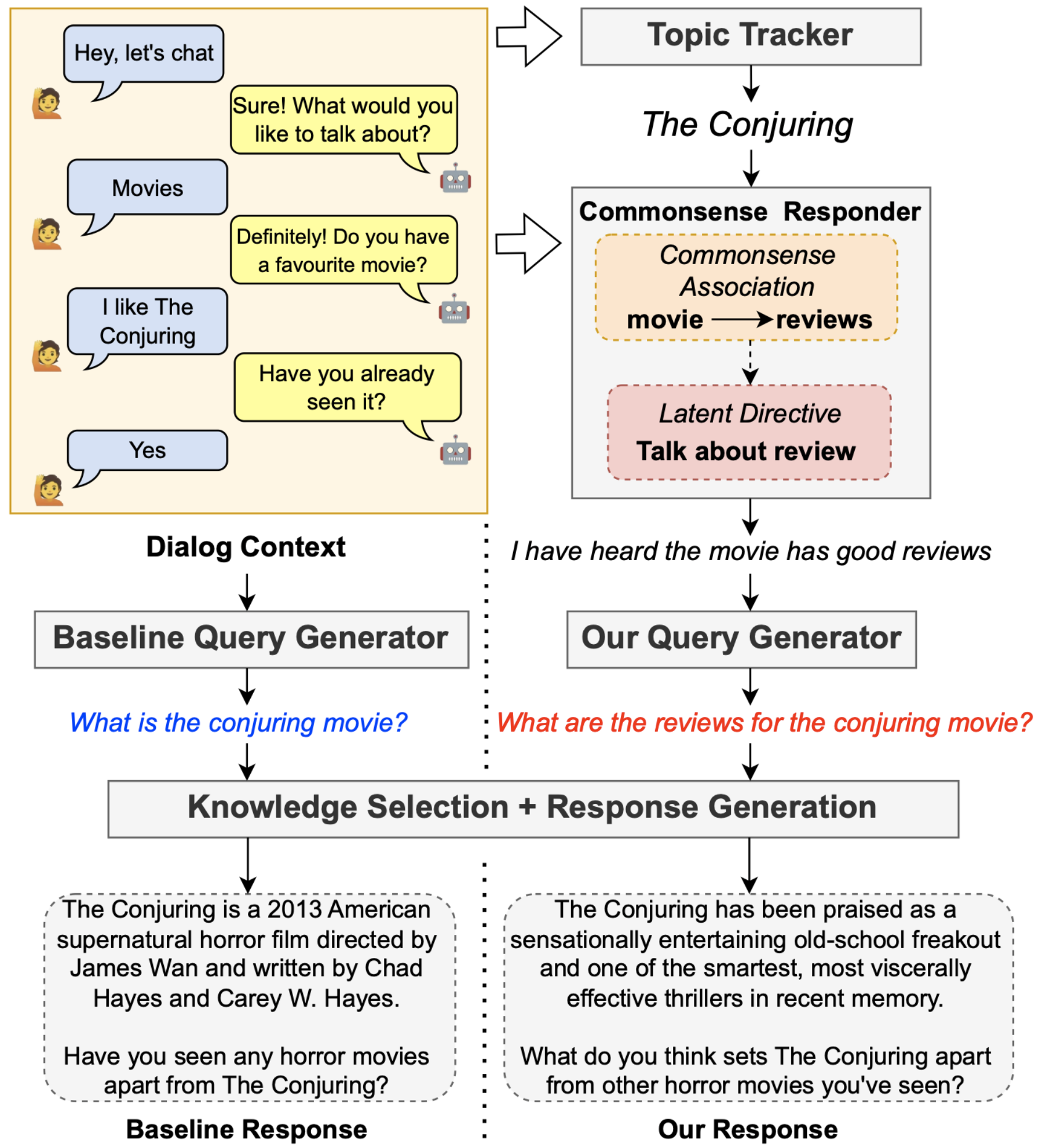
Revanth Reddy, Hao Bai, Wentao Yao, Sharath Chandra, Heng Ji ChengXiang Zhai Findings of EMNLP, 2023 [Paper] To tackle passive conversations, we propose to integrate social commonsense reasoning for the generation of search queries in knowledge-powered conversations. We leverage a commonsense dialog system to establish connections related to the conversation topic, which subsequently guides an instruction-driven query generation model. |
|
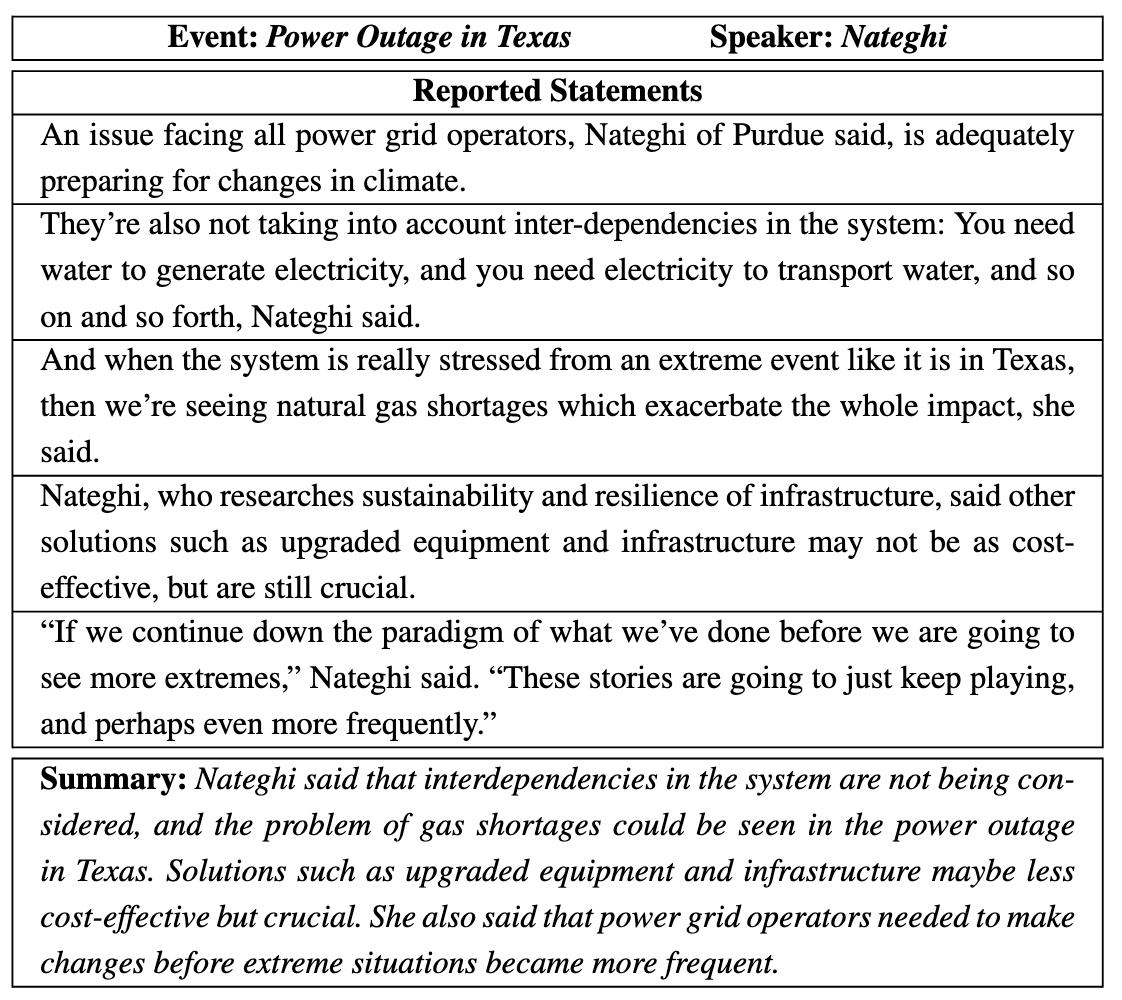
Revanth Reddy, Heba Elfardy, Hou Pong Chan, Kevin Small, Heng Ji AAAI, 2023 [Paper][Poster] We propose the novel task of summarizing the reactions of different speakers with respect to a given event. We create a new multi-document summarization benchmark, SumREN, along with a pipeline-based framework for summarizing reported speech, which generates summaries that are more abstractive and factually consistent. |

|
Revanth Reddy, Sai Chinthakindi, Zhenhailong Wang, Yi R. Fung, Kathryn S. Conger, Ahmed S. Elsayed, Martha Palmer, Preslav Nakov, Eduard Hovy, Kevin Small, Heng Ji EMNLP, 2022 [Paper][Poster] We present NewsClaims, a new benchmark for knowledge-aware claim detection, that re-defines the claim detection problem to include extraction of additional attributes related to the claim. NewsClaims aims to benchmark claim detection in emerging scenarios, comprising unseen topics with no training data. |

|
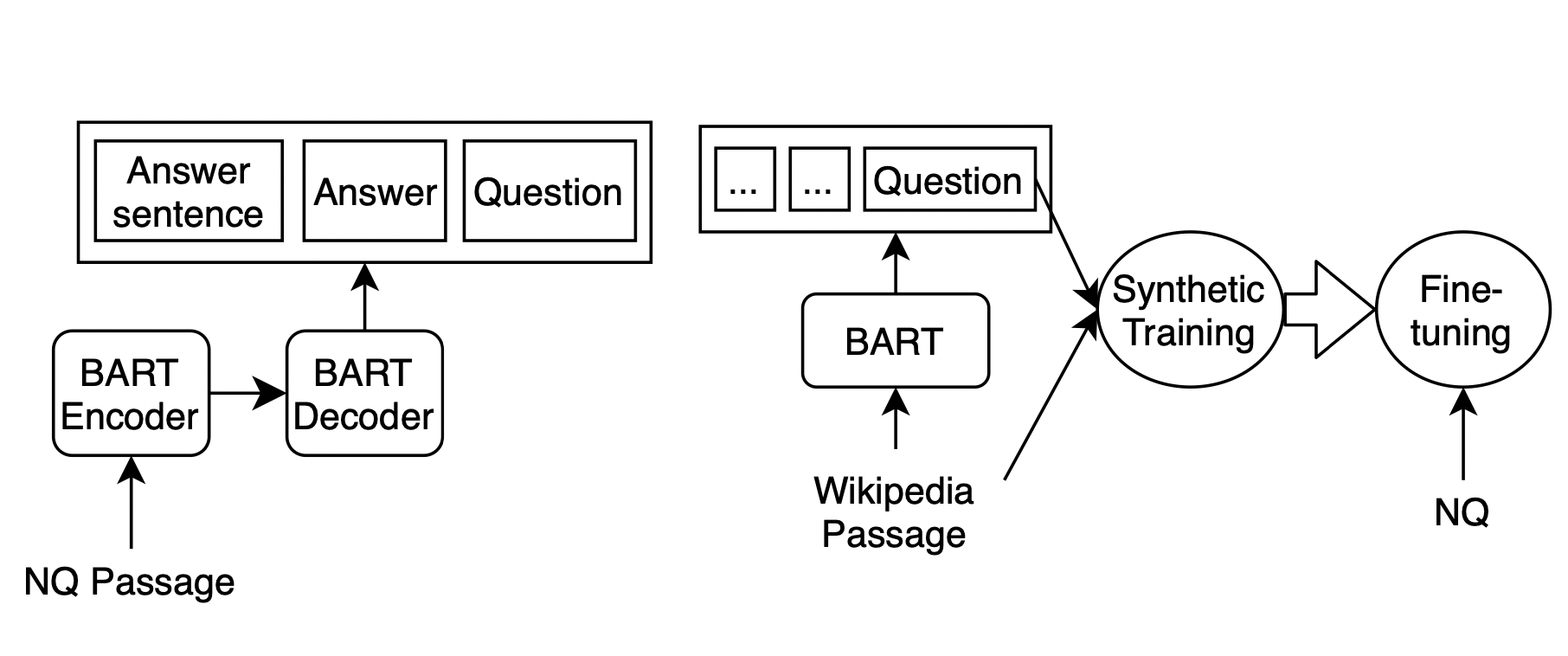
Revanth Reddy, Arafat Sultan, Martin Franz, Avi Sil, Heng Ji SIGIR, 2022 [Paper][Poster] Using a novel targeted synthetic data generation method that identifies poorly attended entities and conditions the generation episodes on those, we teach neural IR to attend more uniformly and robustly to all entities in a given passage. |
|
Revanth Reddy, Vikas Yadav, Arafat Sultan, Martin Franz, Vittorio Castelli, Heng Ji, Avi Sil COLING, 2022 [Paper] We show that synthetic examples generated using a sequence-to-sequence generator can be effective in improving the robustness of neural IR, with gains in both in-domain and out-of-domain scenarios. |

|
Revanth Reddy, Sai Chinthakindi, Yi R. Fung, Kevin Small, Heng Ji COLING, 2022 [Paper][Poster] We propose a fine-grained claim detection framework that leverages zero-shot question answering using directed questions to solve a diverse set of sub-tasks such as topic filtering, claim object detection, and claimer detection. |
|
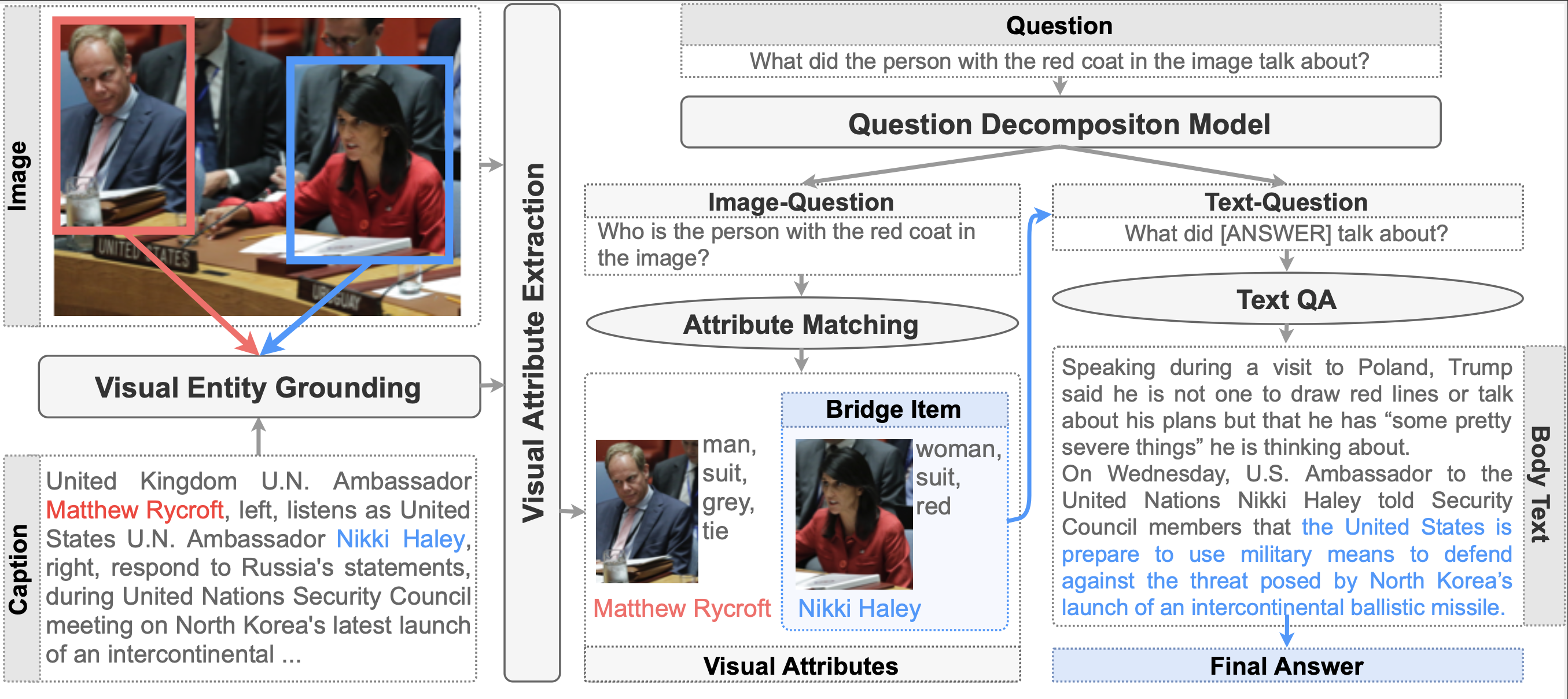
Revanth Reddy, Xilin Rui, Manling Li, Xudong Lin, Haoyang Wen, Jaemin Cho, Lifu Huang , Mohit Bansal, Avi Sil, Shih-Fu Chang, Alexander Schwing, Heng Ji AAAI, 2022 [Paper][Slides][Poster] We propose a new benchmark for multimedia question answering over news articles and introduce a novel data generation framework for generating questions that are grounded on objects in images and answered using the news body text. |

|
Manling Li, Revanth Reddy, Ziqi Wang, Yi-Shyuan Chiang, Tuan M. Lai, Pengfei Yu, Zixuan Zhang, Heng Ji ACL Demo, 2022 [Paper][Demo] We present COVID-19 Claim Radar, a system that automatically extracts claims relating to COVID-19 in news articles. We provide a comprehensive structured view of such claims, with rich attributes (such as claimers and their affiliations) and associated knowledge elements (such as events, relations and entities). |

|
Revanth Reddy, Bhavani Iyer, Arafat Sultan, Rong Zhang, Avi Sil, Vittorio Castelli, Radu Florian, Salim Roukos SIGIR, 2021 [Paper][Poster][Slides] We explore using a synthetic example generation approach to improve the performance of state-of-the-art open-domain end-to-end question answering systems in a specialized domain, such as COVID-19. |

|
Yi R. Fung, Chris Thomas, Revanth Reddy, Sandeep Polisetty, Heng Ji, Shih-Fu Chang, Kathleen McKeown, Mohit Bansal, Avi Sil ACL, 2021 [Paper] While most previous work is on document level fake news detection, for the first time we propose misinformation detection at knowledge element level. It not only achieves higher detection accuracy but also makes the results more explainable. |
|
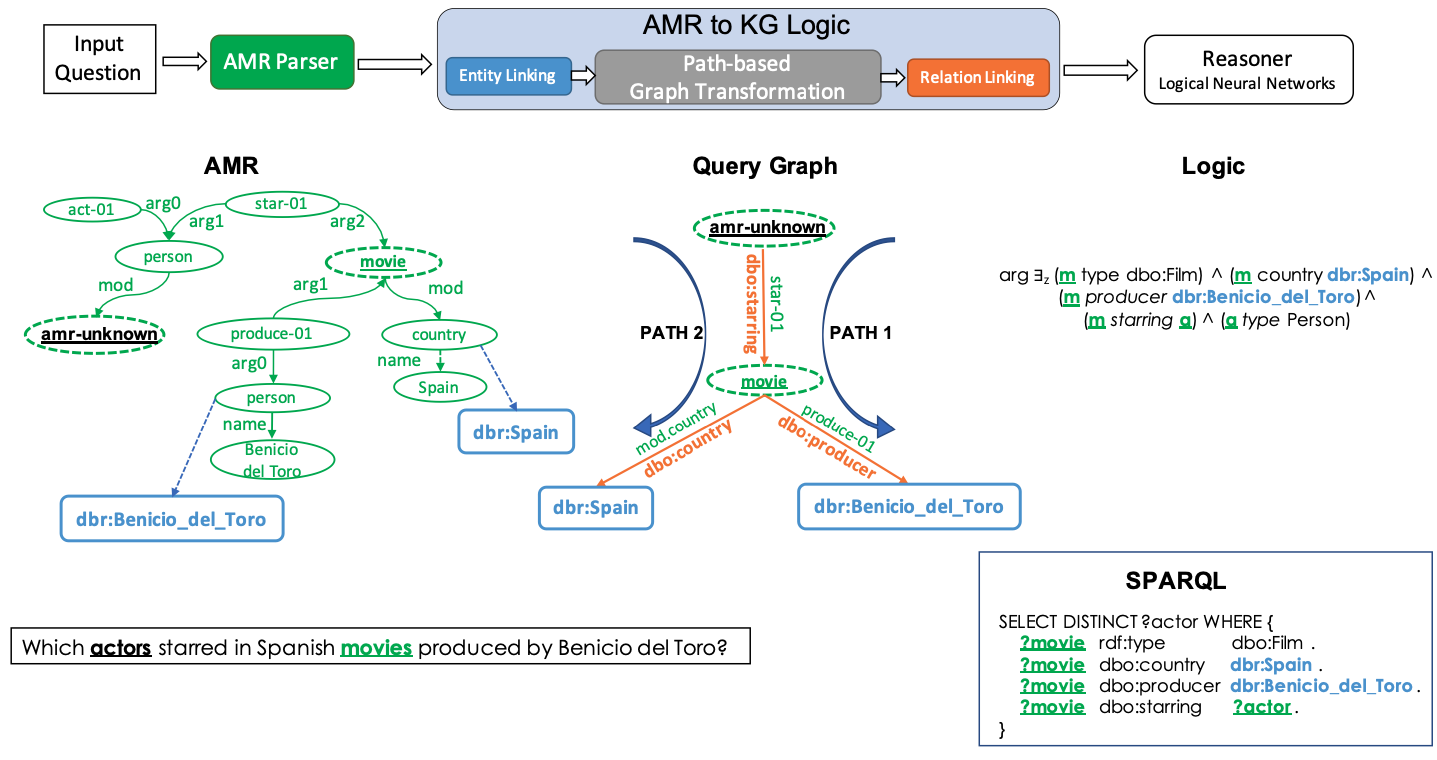
Pavan Kapanipathi*, Ibrahim Abdelaziz*, Srinivas Ravishankar*, ... , Revanth Reddy, Ryan Riegel, Gaetano Rossiello, Udit Sharma, Shrivatsa Bhargav, Mo Yu Findings of ACL, 2021 [Paper] We introduce a neuro-symbolic question answering system that leverages AMR for question understanding and uses a pipeline-based approach involving a semantic parser, entity and relationship linkers and a neuro-symbolic reasoner. |

|
Rong Zhang*, Revanth Reddy*, Arafat Sultan, Efsun Kayi, Anthony Ferrito, Vittorio Castelli, Avi Sil, Todd Ward, Radu Florian, Salim Roukos EMNLP, 2020 [Paper] We formulate synthetic pre-training tasks that can transfer to downstream tasks, by using structure in unlabeled text. We show considerable gains on multiple tasks in the IT domain: question answering, document ranking and duplicate question detection. |
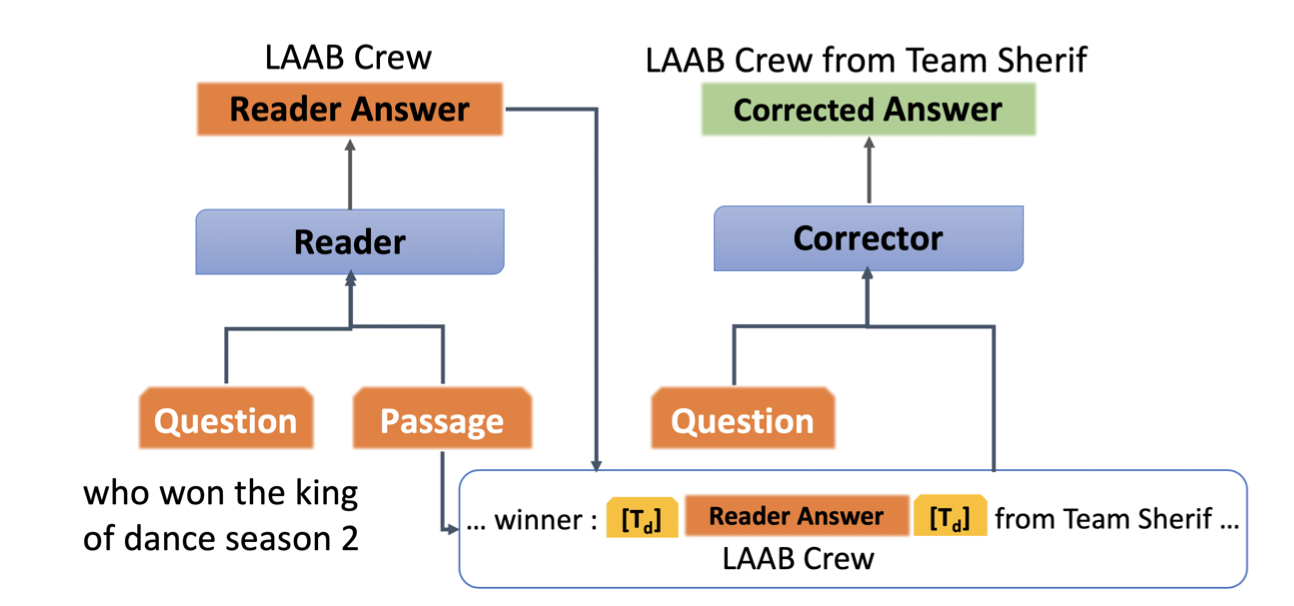
|
Revanth Reddy, Arafat Sultan, Rong Zhang, Efsun Kayi, Vittorio Castelli, Avi Sil Findings of EMNLP, 2020 [Paper] We propose an approach for correcting partial match answers (EM=0, 0<F1<1) into exact match (EM=1, F1=1) and obtain upto 1.3% improvement over a RoBERTa-based machine reading comprehension system in both monolingual and multilingual evaluation. |

|
Young-suk Lee*, Ramon Astudillo*, Tahira Naseem*, Revanth Reddy*, Radu Florian, Salim Roukos Findings of EMNLP, 2020 [Paper] We propose self-learning approaches to improve AMR parsers, via generation of synthetic text and synthetic AMR as well as refinement of actions from the oracle. We achieve state-of-the-art performance in AMR parsing on benchmark AMR 1.0 and AMR 2.0 datasets. |
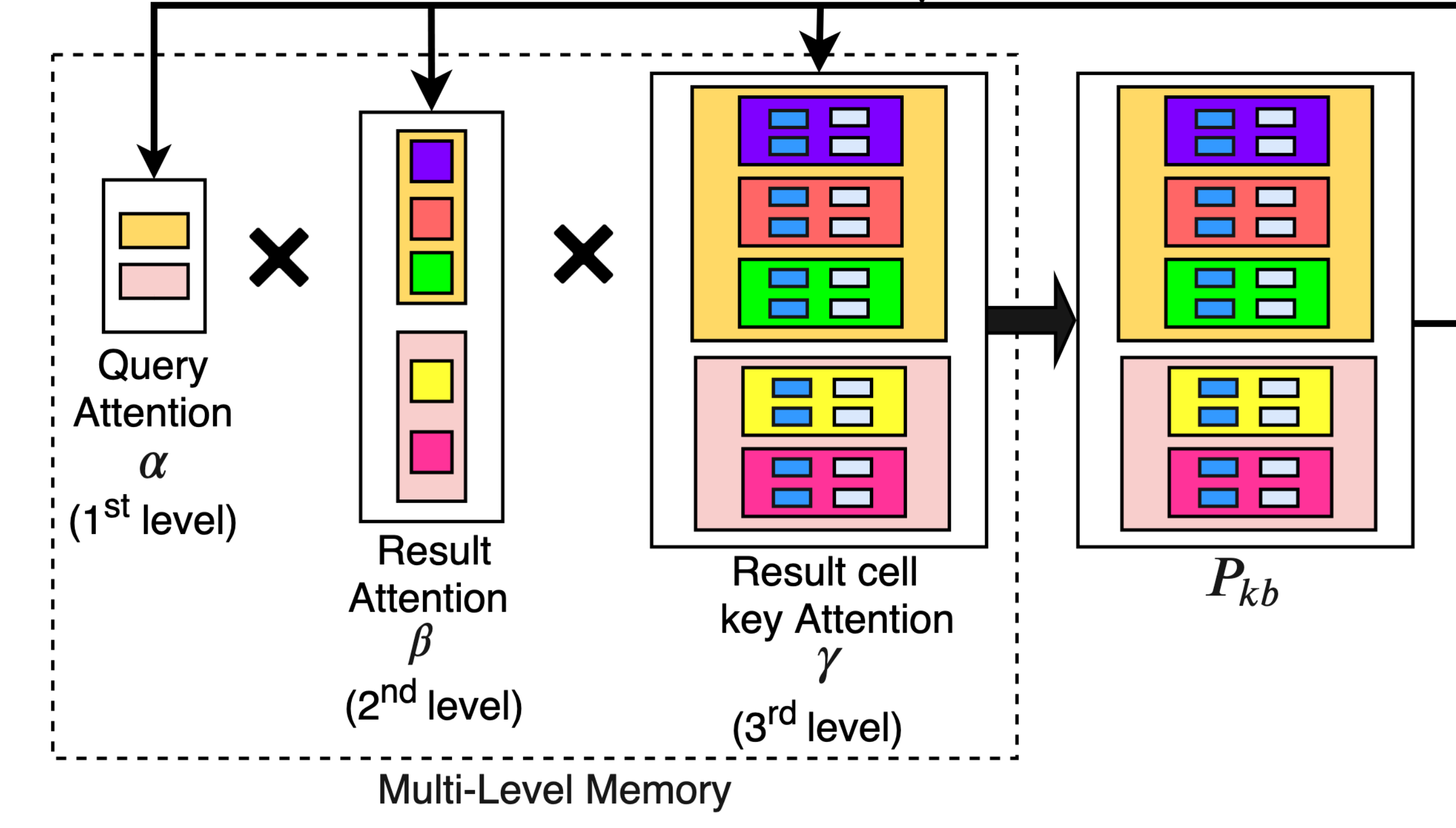
|
Revanth Reddy, Danish Contractor, Dinesh Raghu, Sachindra Joshi NAACL, 2019 [Paper][Poster] We design a novel multi-level memory architecture that retains natural hierarchy of the knowledge base without breaking it down into subject-relation-object triples. We use separate memories for dialog context and KB to learn different memory readers. |
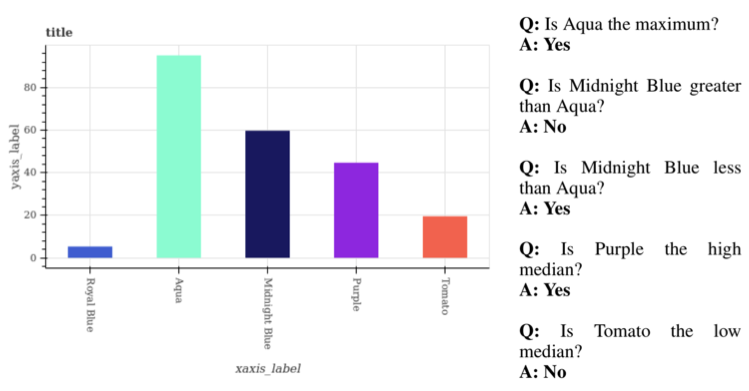
|
Revanth Reddy, Rahul Ramesh, Ameet Deshpande, Mitesh Khapra IJCNN, 2019 [Paper][Slides] We design a modular network that uses depth-wise and 1D convolutions for visual reasoning on scientific plots. We achieve state-of-the-art accuracy on FigureQA dataset, bettering Relation Networks by 7%, with a training time over an order of magnitude lesser. |
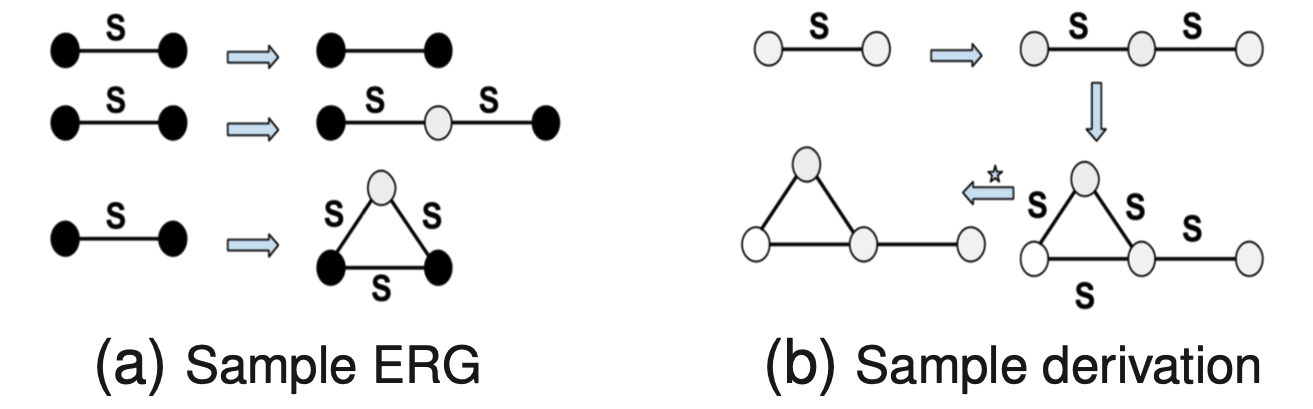
|
Revanth Reddy*, Sarath Chandar*, Balaraman Ravindran SDM, 2019 [Paper][Slides][Poster] We propose a graph generative model based on probabilistic edge replacement grammars. We design an algorithm to build graph grammars by capturing the statistically significant sub-graph patterns. |
|
|